Sometimes it is necessary to restart all nodes in the NSX-T Manager cluster. We call this procedure the Rolling Restart.
In this specific case, because a T0 Gateway showed a Failed status through a false-positive error. In our most recent case, we ran into the issue JDK-8330017.
The following post shows how to restart nodes in the NSX-T Manager Cluster in a step-by-step way.
Login to all of the NSX-T Manager nodes using SSH through the admin account. This will launch the NSX CLI.
The first step is to make sure the cluster state is healthy. You can ascertain this by running the following command
get cluster status
When the Cluster Overall Status STABLE, it is safe to reboot the node

From here we will restart the nodes one by one.
Do this by running the command
reboot
and confirm with
yes

Wait until the node is restarted. You can check its process by checking the console, but also by (regulary) checking the cluster status (get cluster status) through one of the other two nodes.
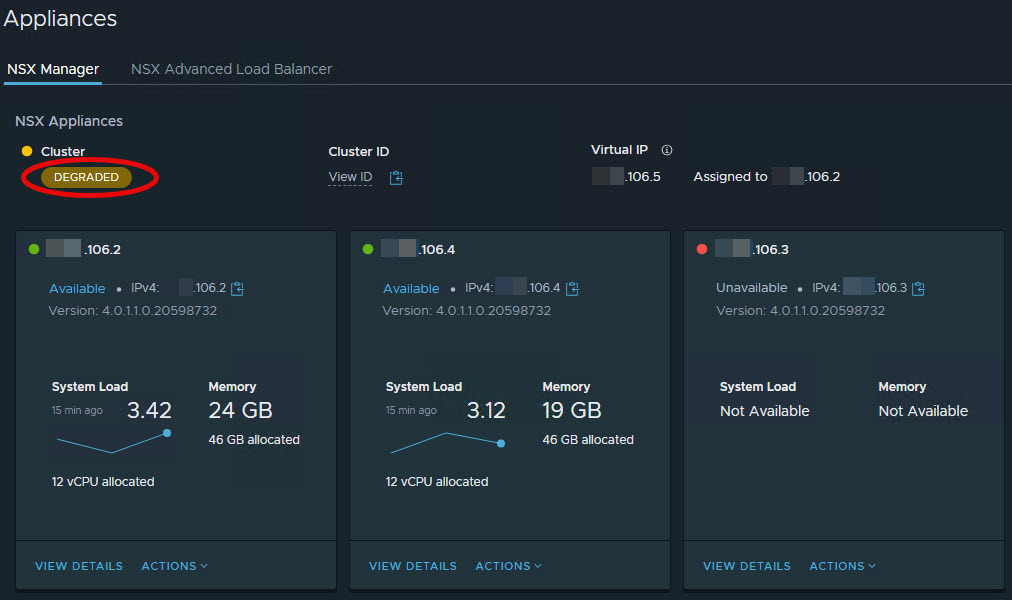
You will see that the NSX-T “Group Types” for the first node will turn DOWN while the NSX-T Manager node is restart. The cluster status will show up as DEGRADED. You will also find this in the NSX-T Manager itself (GUI)

When all Group Types are back to STABLE and the overall cluster status is STABLE is well (get cluster status), proceed with the next node.
In the case that you have restarted the NSX-T Manager node with the cluster IP, the NSX-T Manager (GUI) Interface (https://[NSX-T-Manager]/nsx/#/app/system/home/components) will show the virtual IP has been assigned to another node. In the process you have successfully tested a failover!

Now the error is hopefully resolved